日々の破片
| 著作一覧 |
2011-02-01
_ るびま(続)
32号。
それにしても、るびまのHotlinksのノリだと比較的忠実に喋りが文章になるので、漫才みたいだな(大阪人の喋り=漫才みたいという東の人間ならではの感覚、と思うけど、もしかしたら日本全国そう感じるかも知れないかも)。
2011-02-02
_ リッチーは4ストロークをけちったのさ
a = 3
の等号に引っ掛かるというのは理解しにくい。
ジャンルが違えば意味も変わる。彼らは英国王から拝命されたわけでもないのに、ロード·ヴァルデモートとロードを名乗るあの人が登場した瞬間に理解出来なくなってしまうんだろうか? そういう愚か自慢話(実は単なる「俺様は真実を知ってる蘊蓄」語り)のように聞こえる。
原始、FORTRAN(綴り合ってる?)は
LET I = 0
だった。
LETがあるから、Iを0と等しくしろ、と読み下せる。疑問が挟まる余地はない。
自明なものは取り去るのがUnixスタイルだ。
真偽判断を伴わない
I = 0
の=が等号の意味ではないのは自明だ。
つまりLET は不要だ。そこでリッチーはLETを捨てた。
VBもLETを省略出来るが同じ理由だろう。
まあ、本当にリッチー以降かどうかは知らないけど。
というわけで、そういうところに拘る人は
MOVE 0 TO I.
と書くCOBOLを使えば万事解決だ。
2011-02-05
_ OSXのファイル名について教えてもらったこと
昨日の東京Ruby会議で、かわばたさんからNFCとかNFDとかについて教えてもらった。
Unicodeでは、文字の合成がサポートされている。たとえば「か」と濁点「゛」は合成することもできるし、「が」という1つの文字で登録もされている。しかし「あ」と濁点を組み合わせた1つの文字は登録されていない。でも「あ」と「゛」を組み合わせた「あ゛」も作れる。作った場合にどう表現するかはフォント(描画エンジンかも知れないな)に依存する(日本語よりも、おそらくウムラウトとかを使う欧州言語のほうで意味を持つ仕様だと思う)。
ということは、「が」という文字が実際には登録されている「が」という1つの文字なのか、それとも「か」+「゛」なのかは、特に文字列の比較をする場合には問題となりうる。人間としては等価として扱いたいが、コンピュータとしてはかたや1文字、かたや2文字だからだ。
そこで、アップルは考えた。そういうものはすべて分解して覚えておけばOK。というわけで、とかわばたさんの話は続く。lsすると「が」というファイルは2つに分けて表示される。(一方、マイクロソフトは何も考えていないらしい)
というわけで、合成文字をすべて分解する正規化をNFD、統合する正規化をNFCと呼ぶ(さらにNFKDとNFKCというのもあるそうだ)。
でも、今、10.6のUTF-8ターミナルで試したらちゃんと1文字として表示されている。ということはアップルは修正したようだ。
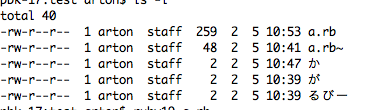 「るびー」の「び」と「−」の間は詰まっているように見える。
「るびー」の「び」と「−」の間は詰まっているように見える。
表示はともかくNFDされているかどうかを調べてみる。
次のスクリプトを実行する。
# coding: utf-8
Dir.entries('.').each do |d|
next if d =~ /^\.|rb~?$/ # このスクリプトやディレクトリは飛ばす。
printf("name='%s', size=%d, encoding=%s\n", d, d.size, d.encoding)
end
出力結果は以下となった。
pbk-17:test arton$ ruby19 a.rb name='か', size=1, encoding=UTF-8 name='が', size=2, encoding=UTF-8 name='るびー', size=4, encoding=UTF-8
sizeを見ると、「が」が2、「るびー」が4となっている。ということはかわばたさんが言った通り、分解されているということのようだ。
実はRubyはこのようなUnicode間の変換をサポートしている。
以下のようにencodeをかけるように修正する。
# coding: utf-8
Dir.entries('.').each do |d|
next if d =~ /^\.|rb~?$/
printf("name='%s', size=%d, encoding=%s\n", d, d.size, d.encoding)
d = d.encode('utf-8', Encoding::UTF8_MAC)
printf("name='%s', size=%d, encoding=%s\n", d, d.size, d.encoding)
end
上でおれはd = d.encode...とか書いているが、ここで情け容赦なくencode!と「Shift-1」を入力する心持ちを「破壊神への精神的脱皮」とか「破壊メソッド呼び出しの悦楽」と呼ぶというのもテーマにあったのを思い出した。おれはストイックだからどうにも悦楽を得られないらしい。しかしその一方で破壊的メソッドを呼び出す精神構造を「リソース貧困なる精神」、非破壊メソッドを呼び出す精神構造を大富豪と、ストイックという点では正反対に見なすことも可能なのだった。)
実行してみる。
pbk-17:test arton$ ruby19 a.rb name='か', size=1, encoding=UTF-8 name='か', size=1, encoding=UTF-8 name='が', size=2, encoding=UTF-8 name='が', size=1, encoding=UTF-8 name='るびー', size=4, encoding=UTF-8 name='るびー', size=3, encoding=UTF-8
encode後、「が」は1、「るびー」は3となった。
成瀬さんGJ!ということらしい。
(外部エンコーディングをUTF-8-MACとすれば最初から合成されるのかな? と試してみるかも)
追記:より深く知りたい人はあまのさんのページを参照すると良いと思います。
_ OSXでのファイル名比較
というわけで、ファイル名をスクリプトで比較する場合、何も考えないとうまくいかないことがある。
普通にエディターでutf-8でスクリプトを書くとそれはutf-8になるし、少なくとも
ruby 1.9.2p0 (2010-08-18 revision 29036) [x86_64-darwin10.4.0]
では、OSXのファイル名を勝手に合成のほうの正規化はしてくれない。
次のようにスクリプトを書いたら期待通りに動作(つまり、特定のファイル名を検出)した。
# coding: utf-8
Encoding.default_external = Encoding::UTF8_MAC
Encoding.default_internal = Encoding::UTF_8
RUBY = 'るびー'
printf("str='%s', size=%d, encoding=%s¥n", RUBY, RUBY.size, RUBY.encoding)
Dir.entries('.').each do |d|
next if d =‾ /^¥.|rb‾?$/
printf("name='%s', size=%d, encoding=%s¥n", d, d.size, d.encoding)
puts 'find!' if RUBY == d
end
実行結果を以下に示す。
pbk-17:test arton$ ruby19 a.rb str='るびー', size=3, encoding=UTF-8 name='か', size=1, encoding=UTF-8 name='が', size=1, encoding=UTF-8 name='るびー', size=3, encoding=UTF-8 find!
Dirクラスが読み込んで文字列を返した時点で、default_externalからdefault_internalに変換され、それがスクリプトのエンコーディング(マジックコメントで指定)で指定したものと一致している。
ではスクリプトをSJISにしたらどうなるんだろう?
と、試したら、スクリプトはSJIS、default_internalはutf-8なのでRUBYという文字列はshift_jisのままなので見つからない状態となった。ということは自動的にやらせるには、default_internalをスクリプトのエンコーディングに合わせてやる必要があるのかな。でも、そうするとスクリプトがライブラリで他の未知のスクリプトから呼ばれるとすると、メソッドに入った時点でdefault_internalを保存、設定、出る時点で復元してやらないとおかしくなるはずだ、というかおかしくなるだろう(呼び出し側に依存するけれど)。
と考えるとクロスプラットフォームで(externalが実行環境によって変わる)かつ、クロスエンコーディング(という言葉があるか知らないけれど、複数のエンコーディングによるスクリプトファイルで構成されたプログラム)は、すんなりとは書けないな。
2011-02-06
_ Rubyはプログラミングをたのしくする……か?
一昨日の東京RubyKaigiの高橋さんの基調講演(なのかな)は、Rubyのたのしさを語るというやつで、「それにしても「Rubyのよさ」を説明しようとして見事玉砕したRubyコミュニティの巨人の連なりに高橋さんも並んでしまったなあ。」と評されてしまっているけど、でもあらためて考えてみるっていう意味ではそう悪くはなかった。
というか、おれははて?と考えてしまったのだった。本当にRubyはプログラミングをたのしくしてくれてるのか?たとえば、最近の仕事をちょっと考えてみる。
C#のWinFormアプリケーションでグループボックス内に可変個のチェックボックスがあり、あるタイミングでそいつらのチェックをすべて解除する。
だいたいそういうプログラムでは山のようにcheckBox1.Checked = false;みたいな行が並ぶものと相場が決まっている。だからもちろんそういう書き方はしない。
すべてのコントロールは内包するコントロールをControlsプロパティに持っている。ということはいちいちチェックボックスのインスタンス変数を操作しなくても次のように記述できる。
foreach (var cb in groupBox1.Controls)
{
if (cb is typeof(CheckBox))
{
(cb as CheckBox).Checked = false;
}
}
でも、ループの中で条件判断するってのは、ポリモーフィズムが利用できるのにswitch-caseを使うくらいばかな書き方だ(効率上の理由であえて選択するってのはもちろんあるので、常にばかな書き方とは言えないけど)。
リスト内包表記のうまみを知ってしまったら、それを利用すべきだ。C#だとそれはつまりLinqだ。
foreach (var cb in from Control c in groupBox1.Controls where c is typeof(CheckBox) select (c as CheckBox))
{
cb.Checked = false;
}
実際問題として、こんなことでもささやかにたのしい。MSDNや言語仕様を眺めてちょっとでもいかした長生きする(=若い)書き方を見つけてその動作を確認して書いてみてそれをものにして使いこなすようになる。新しいことを覚えるのはおもしろく、それを使えればうれしく、実際に意味を持った成果物となればたのしい。
そうか、わかった。なんのことはない。
プログラミングはたのしいのだ。
それがたのしくなくさせるための仕掛けや罠が張り巡らされているので、みんな勘違いをさせられているのだ。
そのため、そういった仕掛けや罠から自由なRubyだとプログラミング本来のたのしさを得られるということではなかろうか。
とすれば、Rubyがたのしいとしたら次の2つの理由からだろう。
1つは、すべてが式だということだ。だから、ステートメント主体の言語と異なり、比較的自由に書き方を変えられる。もちろん、それを言ったら僅かなスペシャルフォームを除けばすべてが自由なLispのほうが上かも知れないけど(スペシャルフォームをマクロの中に閉じ込めれば事実上なんの制限もないことになるし)、にもかかわらずS式のような形式の押し付けがない。オープンクラスというのもこっちの理由となる。sealやfinalといった愚かな制約のせいで、どれだけJavaやC#の魅力が損なわれたことか(C#はそれを救済するためか、妙な静的メソッドの追加機能が後から付いたけど)。
もう1つは、それが少なくとも10年前は、メインの仕事言語ではなかったということかも知れない(おれにとっては今もメインの仕事言語ではない)。
メインではないということは、どう書こうがどう使おうがおれの自由だということだ。
前者は技術的な制約からの自由をもたらすものであり、後者は社会的な制約からの自由をもたらすものだ。たのしいことだ。もちろん自由というのはたのしいということだ(そいつに伴う責任とかを勘定に入れてさえも)。
というわけで、おれが疑問でしょうがないのは、前田修吾さんのプログラミング規約(まあ、必要性がわかってしまうところはあるけれど、それはおれのたのしくない側面なのでしょうがない)とかにしたがっているかどうかのチェックを受けたり、SIer的な箸の上げ下ろしまで指定した詳細設計書みたいなものを元にプログラミングしたとしても、それでもRubyでプログラミングするのはたのしいのかどうかだ。もし、こういった制約があっても、それでもたのしいのだとしたら、おれはその理由を実に知りたい。
 たのしいRuby 第3版(高橋 征義)
たのしいRuby 第3版(高橋 征義)
_ kitajgj
とまあ結局プログラミングはたのしく、それはマシンを駆る万能感に由来すると思うし、その意味じゃバイク乗りと大して変わらないわけで、制約が少なくやり方はたくさん、やり方がたくさんということは、昨日のおれより今日のおれという成長感を得られやすく、それなりに厳しくもあり優しくもあるコミュニティがあり、そういった成長を助けてくれる雰囲気が醸成されている、そういったことが理由ってことだろう。
で、それを一言でしめしたのがkitajさんの名言、さすがバイク乗り、皮膚感覚でわかってる、ってことだな。
2011-02-07
_ WIN32OLEの高速化手法
一昨昨日の(「さきおととい」って、「昨」がだぶるになるのか!)東京Ruby会議で、WIN32OLEででっかなXLSファイルをいじくると遅いというので、ActiveScriptRubyを使えば10~100倍速いと言ったけど、実測してみたら悪い方にでたらめだった。すみません。
というわけで、高速化について実測した結果を元に示す。
ある程度遅くなければ意味がないので、まっさらなワークシートに10000行、A~Zの26カラムへWIN32OLEを利用してデータを設定するスクリプトを利用する。
次のスクリプト(xls.rb)を出発点とする。
#coding: cp932
require 'win32ole'
xl = WIN32OLE.new('Excel.Application')
xl.visible = true
book = xl.workbooks.add
start = Time.now
1.upto(10000) do |row|
?A.upto(?Z) do |col|
if row.even?
book.worksheets(1).range("#{col}#{row}").value = 3
else
book.worksheets(1).range("#{col}#{row}").value = 'こんにちは'
end
end
end
puts "Elapsed time: #{Time.now - start} secs"
実測すると、159.45412秒を得た(Core-i5系Xeon、6GB、Windows7(64)、Excel2010(32))。
最初に行うべき最適化は、ループの中に2行(もっとも実行は都度1回)あるbook.worksheets(1).range("#{col}#{row}").value = の変形だ。
この記述は以下のように動作する。
book - 外部プロセス呼び出し - worksheets(1) - 外部プロセス呼び出し - range(...) - 外部プロセス呼び出し - Value=
この記述のうち、book.worksheet(1)の呼び出しは、指定されたWorkSheetオブジェクトの取得をループの外に出すことで回避できる。
修正後のスクリプト(xls2.rb)を次に示す。
#coding: cp932
require 'win32ole'
xl = WIN32OLE.new('Excel.Application')
xl.visible = true
book = xl.workbooks.add
start = Time.now
sheet = book.worksheets(1)
1.upto(10000) do |row|
?A.upto(?Z) do |col|
if row.even?
sheet.range("#{col}#{row}").value = 3
else
sheet.range("#{col}#{row}").value = 'こんにちは'
end
end
end
puts "Elapsed time: #{Time.now - start} secs"
sheetへの設定をループの外へ追い出したため、ループ内での呼び出しは、sheet - 外部プロセス呼び出し - range(..) - 外部プロセス呼び出し - Value = と2/3に減少する。
実測すると、122.374999秒と、元の処理時間の3/4となった。
ここで、ActiveScriptRubyを使うことで外部プロセス呼び出しのオーバーヘッドがなくなるので、一気に1/10となるかと思ったが、良く考えてみたら、外部プロセス呼び出しのオーバーヘッド2/3で、処理時間3/4なのだからそんな極端な高速化は期待できないことになる。
以下の例では、Ruby-1.9.2配布パッケージに含めているRScript19を元にする。このバージョンではインストール直後からRubyize機能(OLEオートメーションで処理可能なRubyオブジェクト化)が利用できるからだ。いわゆるASRの場合、インストールディレクトリのsampleディレクトリ内のRubyizeサンプルを自力でRegsvr32を利用して登録する必要がある。
以下のスクリプトを用意する(xlsemb.rb)。
#coding: cp932
class Filler
def fill_three(book)
start = Time.now
1.upto(10000) do |row|
?A.upto(?Z) do |col|
if row.even?
book.worksheets(1).range("#{col}#{row}").value = 3
else
book.worksheets(1).range("#{col}#{row}").value = 'こんにちは'
end
end
end
"Elapsed time: #{Time.now - start} secs"
end
end
Filler.new
これまでのスクリプトと異なり、与えられたWorkbookオブジェクトを操作するメソッドを持つオブジェクトを返すスクリプトだ。
このスクリプトを新規Excelブックの適当なセル(以下の例では2シート目のA1)の中へ貼り付ける。これはVBAの中では複数行の文字列がヒアドキュメントのようには簡単に記述できないからで、別にVBAのコード内へ文字列として記述しても良い。
次に、Excelに次のマクロを作成する。
Sub fillbyruby()
Dim ruby As Object
Dim filler As Object
Set ruby = CreateObject("ruby.object.1.9")
Set filler = ruby.erubyize(Sheet2.Cells(1, 1).Value)
MsgBox filler.fill_three(ThisWorkbook)
End Sub
fillbyrubyマクロは、ruby.object.1.9(これはRScript19のRubyizeクラスのプログラムID)のerubyizeメソッドへスクリプトを流し込み、返されたオブジェクト(ここでは上に示したスクリプトなのでFillerクラスのインスタンスとなる)のfill_threeメソッドをThisWorkbookを引数として呼び出し、結果をメッセージボックスに表示する。つまり、先に示したスクリプトを実行し、経過時間をメッセージボックスに表示する。
実行結果は、元のxls.rbの2/3以下ではあるが、98.273621秒とまったくふるわなかった。
そこで、再度、呼び出し削減(この場合は内部プロセスサーバ呼び出しのはずだが)修正をかけて、次のスクリプトをシート2のA1に張り付けた。
#coding: cp932
class Filler
def fill_three(book)
start = Time.now
sheet = book.worksheets(1)
1.upto(10000) do |row|
?A.upto(?Z) do |col|
if row.even?
sheet.range("#{col}#{row}").value = 3
else
sheet.range("#{col}#{row}").value = 'こんにちは'
end
end
end
"Elapsed time: #{Time.now - start} secs"
end
end
Filler.new
結果は、75.0033秒となり、最初のxls.rbの1/2以下となった(が、おれの期待よりは遅い。1/3になるかと思っていたからだ)。
まとめ
外部プロセス呼び出し回数は可能な限り削減する。そのためにはobj.obj.obj.methodのような記述を避ける。
期待外れとはいえ、実行時間が短縮できるのは事実なので、可能な限り生Ruby.exeを利用した外部プロセス実行ではなく、Rubyizeを利用した内部プロセス実行を利用する。この場合、ExcelマクロとしてXLSファイルへ内包できるという利便性も得られる(もちろん、実行環境にASRがインストールされていることが前提となる)。
(蛇足の考察):それにしても遅いのは、Rangeオブジェクトが次々と生成/廃棄されるのでGCのオーバーヘッドが大きいのではないか、と推測している。
(蛇足の追加):RScriptはRubyとクライアントのスレッドを分離しているから、スレッド間通信(プロセス間ほどではないが相当なオーバーヘッドがある)しているというのを忘れてた。なので、こんなものかと納得した。
2011-02-08
_ Visual Studioでのエラー
なんか間違えたらしくerror C2259 という ATL::CCOmObject
いくらソースを眺めてもわからない。
検索したら、SQL Serverのフォーラムに良いサジェスチョンがあった。
曰く、エラーメッセージは意味がないから、出力ウィンドウを見ろ。
おお、なるほど、と、タブをめくって出力ウィンドウを見たら関数名が特定されていた。
2011-02-09
_ Rubyizeのインプロセス/インスレッド化
一昨昨昨日の東京Ruby会議でWin32OLEについて話したことが正しくなかったということを昨日書いた。
それでは一体、インプロセスかつインスレッドならどのくらいの速度になるのだろうか?
作って試してみた。
元々98.273621秒だったxlsemb.rbは20.201156秒となった。
次に75.0033秒だったxlsemb2.rbは18.596063秒となった。
元の外部プロセス呼び出しが約160秒だったから、1/8に高速化したことになる。クロススレッド版と比較しても1/4。
結局、通信は遅いといういつもながらの知見となるのだった。
興味がある人は、インプロセス版RubyizeオブジェクトをGRScript19-1.3.0.zipに置いたので使ってみてください。
インストール方法:Administrator権限で(Ruby-1.9.2インストールパッケージを利用するとスタートメニューにRuby Console(Administrator)というのが作られているのでそれを利用する)Ruby-1.9.2をインストールしたディレクトリのbinディレクトリへGRScript19.dllをコピーする(置き換える)。
次に、同じディレクトリでコンソールからRegsvr32 GRScript19.dllを実行する。新規にRubyizeのレジストリ登録が必要なため。
インプロセス/スレッド版のRubyizeのProgIDは、"rubyize.object.1.9"なので、VBAで利用する場合は、 Set ruby = CreateObject("rubyize.object.1.9")のように記述する。
_ 一方ソ連では鉛筆を使った
ラウンドトリップを減らすとか、通信先のノードを自ノードにするというような方法とは別に、そもそも細かな単位では通信しないというやり方があって、もちろん速いはずだ。
テキストの設定で良いのなら、クリップボードでの一括転送という方法がある。via @jitte どうもありがとう。
2011-02-11
_ 感覚の違い
みねこあさんの『「気が狂っている」感触』を読んでいて思い出したことがある。
10年以上前のことだと思うけど、アメリカのどこかの会社の出張RDBセミナーみたいなのに出たのだが(日本に出張してセミナーをしてくれたのだが、黒と赤と青の3色のボールペンを使って分析したことは覚えている)、そこで講師の見るからに賢そうな女性が、1対1の例として墓(tomb)のことを持ち出してきた。
で、おれは日本では1対1じゃなくて多対1だと何気なく言ったらさあ大変。いきなり興奮してそんな気持ちが悪いことはあり得ない、それは異常だ。それはあり得ないからお前はおかしいとか、まさに気が狂っている扱いだった。いや、おかしいのはお前の頭だろうと思ったが、後になって考えてみると、あの連中は野蛮だから土葬なんだな。で、連中の狭い了見で死体と死体がミソくそ一緒に押し込められているところでも想像したのだろうと納得してみた。が、今になって思うと、火葬であってもRIPは個人に対して付けられるようにも思えるから、火だろうが鳥だろうが土だろうが、1対1以外はあり得ないという感覚なのかも知れない。宗教もからんでくるから面倒なことである。
さて、ここでtombは日本の場合、ふつうは何々家で1つだが、少なくとも墓石の下では骨壺は個別になっている。
そこでその狭い了見で骨壺と個人は1対1と説明したら、そうではない文化の連中が、いやおれのところでは多対1だと言い出したら、あそこまで激昂するだろうかな? おれは少なくとも、ほおそういう文化なのですな、と興味深く思うだけだが、そうではない人もいるのだろうか? それは個人的な感覚なのか、広く国民的(あるいは宗派的)な文化感覚なのか、どうなんだろうか。
2011-02-12
_ AJAX
以前買ってなぜか読まずに積んでた本を読んでいると不思議な文字を脇に書いたトラックのイラストが出ている。
 チャンピオンたちの朝食 (ハヤカワ文庫SF)(ヴォネガット,カート,Jr.)
チャンピオンたちの朝食 (ハヤカワ文庫SF)(ヴォネガット,カート,Jr.)

そういう意図(カート・ヴォネガットは読んでること前提的な)を持った名前だったのだろうなぁ。
追記:どうも読んだことがあるような、いやでもそれはローズマリーさん(追記:いやロジャーウォーターズさんだったようなそれはピンクフロイドのような)のほうだったような、とか気になってきて調べるとやっぱ読んでた。
2011-02-13
_ SQLite3メモ
Download pageには、Windows用のバイナリが用意されている。
しかし、DLLはあってもインポートLIBが無い。ヘッダはsqlite-amalgamation-*.zipにあるけれど。
インポートLIBは無いがDEFファイルがDLLに同梱されている。
LIB /DEF:sqlite3.def
で作れる。(HowToCompile)
ソースからVSでビルドする場合については、Building SQLite3 with Visual Studio 2005。
_ IS04ファーストインプレッション
IS03を買うつもりだったがなんか出遅れたので結局IS04を買った。
これでおれもアンドロイドユーザだ。後ろからついては来ないで胸ポケットに収まるだろうけど。
で、どうしてもそれまで電話以外では同じような役回りをしていたiPod touchとの比較になってしまうのだが、うーん、あまり良くはない。
ただ、2日ほど使ってみたが、電話はふつうに使えるし、予想していたよりは反応速度も悪くなく、電池のもちは最初WiFiをONにしっぱなしだったら3時間程度でしおしおして来たが、加減がわかってくると1日はもちそうな感じはする(待ち受けにしている分には余裕な感じだが、もちろんしょっちゅういじくるつもりなので、実際のところは平日に運用しないとわからない)。
iPod touchより遥かに軽く感じるので胸ポケットに入れても引っ張られる感じが皆無なのは良い点だ。一方、右わきのボタンが邪魔くさい(最初、すぐにスリープボタンを押してしまって使いにくかった)。
では、何がiPod touchと比べてうーんなのかというと、まずは、ロングマンと大辞林がしょぼい(iPhoneアプリケーションとAndroidアプリケーションの比較ということになってしまうが)。
iPhoneアプリケーションのその2つについては、大辞林はカテゴライズされた索引があるので、歴史とか人物とかから適当にブラウズすればいくらでも読めるわけだし、リンクも張り巡らされている(適当に選択すればジャンプもできる)。ロングマンは音声もあれば(これは結構役に立つ)同じく英英-英和リンクや語間のリンクもあってばっちりなのだが、こういった良い機能がまったくない。そもそも、選択してコピーができないのだが(ここだけでなく、他のアプリケーションを含めて全体にクリップボードのサポートがまったく欠如していたり、異様に選択しにくかったりするが、これは非常に悪い点だ)、何を考えているんだ?
そもそもアプリケーションではなく、デ辞蔵とかいう無料ビューアに対するデータという形式での販売(大辞林はau Oneで、ロングマンはAndroidマーケットと異なる販売場所なのだが)なのが良くわからない。もしかしておれは違うものを買ってしまったのかも知れないが、いずれにしても辞書を買ったつもりだったが単語帳がやって来たというくらいのしょぼさだ。がっかりだよ。というわけで、デジ蔵辞書と書いてあるものはお勧めできない。ちゃんとしたソフトウェア会社のまともな辞書アプリケーションを購入しないとすごく悲しい思いをすることになる。

そういえば、期待の高速通信ってのも全然だめなような気がする。最初、大辞林のダウンロード(最初に購入した時点ではダウンロードをするためのアプリケーションが降ってきて、次のそれを実行すると本当のダウンロードが始まる)が全然終わらなくて何が起きたのかと思った。で、10分くらい我慢していたが、結局キャンセルしてWiFiにつないだら数分で完了した(まあ、100数パーツを最初の10と残り90で分けたのだが、最初の10の実サイズがわからないのでもしかしたら経過分数に比例したサイズという可能性もゼロではないとは思うが)。というわけで定額通信なのに、家で使うときはWiFiで使うというお粗末さまな感じだ。
で、その衝撃が大きすぎて袈裟までにくい感じだ。
あと、なにこれと思わずおののくアイコンの数。こんなのが4面もある。ああ、日本のPCのプリインストール地獄ってこれのことか(自作-デルというPC歴なので話でしか知らなかった)と思わず納得の東芝+富士通。

2011-02-14
_ Rubyで誰がいつ呼んだか調べる
Railsが、どのタイミングでWEBrickに決めているのか調べようとしたのだが、rackまで入り込んでてやたら面倒なことになっている。で、ソースを頭から読むのは早々に諦めた。
で、WEBrickの先頭にp Thread.current.backtraceと書いてRackのhandlerってやつだと突き止めた。
最初、Exception.new.backtraceと書いたらnilだったのでJavaとは違うなと、あらためて思ったりした。
2011-02-15
_ オブジェクトコレクションから特定の型を取り出す(C#)
コレクションから特定型を抜き出すLINQの例を書いたら、もっとうまい方法をはてぶで教えてもらった。
元はこんなの。
foreach (var cb in from Control c in groupBox1.Controls where c is typeof(CheckBox) select (c as CheckBox))
{
cb.Checked = false;
}
確かに長いな。
で、OfTypeを使ってみる。
using System;
using System.Collections;
using System.Linq;
public class OfType
{
public static void Main()
{
var list = new ArrayList();
list.Add(1);
list.Add("abc");
list.Add(3.0);
list.Add("hello");
list.Add(new ArrayList());
list.Add(new string[] { "a", "b" });
foreach (var s in list.OfType<string>())
{
Console.WriteLine(s);
}
}
}
実行すると、"abc"と"hello"だけが出力される。
(というか、この機能があれば、objectコレクションで十分に便利だな)
で、最初、using System.Linqを書いてなかったのでコンパイルエラーになったわけだが、拡張メソッドらしさが満喫できてちょっとおもしろかった。
2011-02-16
_ 実践F#
1週間前くらいに読了した。チュートリアル的な章なしで頭からお尻まで通して読めるという点で「実践」というのとはちょっと違うかなという気もするが、それはそれとしてワークフローの章がやはり白眉だったかな、と思う。
タイポの続き。(まだ、サポートページは無いようなので、ここで公開)
P.273 「見立てを変えたことで」→「見立てを変えたところで」
(このタイポは日本語ならではでちょっと面白い)
P.291 SEACRET → SECRET (のタイポだと思う)
P.311 「ライブラリ使い方」→「ライブラリの使い方」(あと、文のつながりが今ひとつに思える)
P.322 「説明しまし。」→「説明しました。」
P.397 「表11-9」→「表11-10」
(おれもやってしまうが、後から表番号をふるので本文と微妙にずれてしまう問題かな)
P.408 「呼ばれるます」→「呼ばれます」
(内容的にはどんどこおもしろくなってくる出鼻を挫く不思議語尾。おそらく、この内容の興味深さから、ごく初期に執筆していて、それは常体だったのを後から敬体に変えたための修正漏れとおれは読んだ)
P.433 「表12-3」→「表12-4」
(この節を読んで、C#でもLINQを使い倒すべきだなと感じたので、結構おれ的には重要な個所)
 実践 F# 関数型プログラミング入門(荒井 省三: いげ太)
実践 F# 関数型プログラミング入門(荒井 省三: いげ太)
読後感としては、この本は不思議な本だ。他の関数型の本とは雰囲気があまりに異なるからだろう。要するに、何も構えていないというか、技術者目線に徹しているから(他の関数型の本はおれにはどうも研究者目線というかある種の構えが入ることが多いように(ふつけるにしても)感じる)だと思う。ただ、あまりにも普通の技術書なので、逆にこれを読んでも(まったくの初めてだと)何もアプリケーションは開発できないんじゃないかと感じる。というか、さてどうしようかと(が、別件が少しずつ積まれたので、しばらくはF#では遊べないのであった)。
2011-02-20
_ Javaには良い点があるのか?
Javaは本当に良く使われているプログラミング言語だから、プログラミングを知らない人でもプログラムを記述できる。プログラミングを知っているというのは、この場合、ケースバイケースで記述することができるってことだ(というか、正直なところおれが知っているプログラミングはそのあたりまでで、ケースはわかってもプログラミングがわからなくて、まずいプログラミングをすることもたくさんある)。
そのため、プログラムとは言えないソースコードをたくさん目にする機会があってうんざりした。
どのくらいうんざりしたかと言うとコーディングの掟というケーススタディ本を上梓できたくらいだ。
 コーディングの掟(最強作法) 現場でよく見る不可解なJavaコードを一掃せよ! (開発の現場セレクション)(arton)
コーディングの掟(最強作法) 現場でよく見る不可解なJavaコードを一掃せよ! (開発の現場セレクション)(arton)
というわけでうんざりしているのはJavaで書かれた妙なコードであって、Javaそのものはそれほど嫌いではなく、むしろ好きな部類に入る。interfaceがある言語は(それがヘッダの関数プロトタイプですら)好きだし。
そういうおれにとって、実に楽しく読めた本をオライリーから頂いたので紹介する。
 Java: The Good Parts(Jim Waldo)
Java: The Good Parts(Jim Waldo)
一言で説明すると、Javaの中の人が、Javaのコアなパートの良いパートについて、なぜそのパートが必要で、いかにそのパートを実装すべきで、どういう制約や考慮点があって、実際にどうそのパートを実装して、したがってこう利用しろといったパートについて、おれが教えてやる(と言うほど偉そうな感じはないか。おもしろいトピックだから教えてやるよ、っていうくらいのノリかも)という趣の本だ。
この本は技術エッセイとでも呼ぶべき性質のものだから、読みながらコンソールを叩いたりする必要は特にない。だから売り出されたら(売り出されるかどうかはわからないけれど)O'Reilly Japan Ebook Storeから電子書籍版を購入して移動メディアに入れておいて、拾い読みしたりするのにも向いていると思う。
著者はSunの研究所で分散システムをやっていた人らしい。それだけにRMIについて書いてあるパーツはとりわけおもしろい。RPCで継承を持つ型のオブジェクトを送る場合にピアでそのオブジェクトの実際の型を特定するのは難しいのでCORBAでは事実上リファレンスのみを扱うようにしているが、RMIはシリアライゼーションを使えるので本物の型を与えることができる、といった記述があるが、何気なく使ってはいるがそうかシリアライゼーション(と、おれは『シリアライゼーション』と書いているけど、本書ではこの用語については、きちんと『オブジェクトシリアライゼーション』と限定修飾子をつけて久野先生に怒られないよう考慮してある)という考えそのものが重要だったのであるな、と気付かされたり。
次のパートはどういう意味だろう?
オブジェクトシリアライゼーションは、どんなリモートプロシージャコールシステムにも存在するオブジェクトのマーシャリングおよびアンマーシャリングとほとんど同じように見える。
え、何それ? 同じことなんじゃないの? と驚いて続く文章を読むと、え、何それ……しょぼい、みたいな答(それより未来から過去の話を読むと結構あることだ)を与えられてびっくりするのだが、とにかく、なぜマーシャリング/アンマーシャリングという用語を使わなかったのか、ここに解答があるようだ。つまり、オブジェクトシリアライゼーションは、マーシャルのようなちゃちなものとは違う! という自負というか(……多分)。
取り上げられているパーツは、・型システム(これは好き)、・例外(まあ、中の人だし)、・パッケージ(文句なく同意)、・ガベージコレクション(というか、目次のインデントは編集ミスだな)、Java仮想マシン、Javdoc(良い点に目をつけた)、・コレクション(まったくだ)、・RMIとオブジェクトシリアライゼーション(赤い王子様の本もよろしく)、並行処理(ふむ)、エコロジー(IDE、JUnit、FindBugs)。それぞれ、基礎となる背景説明などがあって、次に見るべき観点ごとに書いている。
それにしても、こういう腰を落ち着けて書かれた技術読み物っては、やっぱり良いな。本当におもしろかった。
追記:糞も味噌もいっしょにSQLExceptionというたわけた仕様があるが、RemoteExceptionについての記述を読むと理屈がわかった。というよりも、型システムのところで明確にされているが、インターフェイスはセマンティクスの上位概念という強い設計思想で統一されているからだ。したがって、SQLExceptionというインターフェイスが示すセマンティクスについて、内部状態を参照することで明らかにすること(そのためのプロパティをオブジェクトは持っている)はプログラマの役割となる。(逆に、そこが実用言語としてのたわけっぷりとなるわけだが、このアカデミズム(実用性に打ち勝つ設計思想の強度をここでは学者的としてこう呼んでみた)とプラグマティズム(と実用主義を訳してみる)のバランスの微妙さ(絶妙では断固として無いね)がJavaのおもしろさ。
_ メソッドは状態なのだろうか?
drubyの実装がどうなっているのか興味はあるところだが、メソッドは状態だろうか、それともインターフェイスだろうか?
もしそれが状態であるならば、リモート呼び出しで値として転送することが可能だ、というよりも可能であるべきだ。
もしインターフェイスならば、それを転送する必要はない。プロクシ(スタブ)で用意すれば良い。
今、JavaScriptのオブジェクト転送を考えてみる。
var o = new Object();
o.state = 'hello';
// oはhelloを持つstateという状態を持つ。当然、oをjsonにマーシャルして送ることは可能。
// では
o.abc = function() { alert('abc'); }
// oはabcをポップアップするabcという状態を持った?
// oをマーシャルすると{ "state": "hello", "abc" : "function() { alert('abc')" } となる?
// でも、それ単なるStringだし。
関数がファーストクラスオブジェクトであるならば、それは転送できて当然だ(なぜならばファーストクラスオブジェクトだからだ)。JavaScriptの場合、jsonの範囲では関数はファーストクラスオブジェクトではないということになる。
突然、C#の拡張メソッドについて思いつくが、つまりあれは「拡張」であるから、ファーストクラスオブジェクトではない。当然、転送はできなくてもしょうがない。
2011-02-21
_ Javaのバッドパーツ
おれは、インターフェイスが大好きで、何はなくともインターフェイス、でも人と人とのインターフェイスは面倒なんでそれほど好きではないが、それは余談だ。
で、
Java: The Good Parts(Jim Waldo)
ただねぇ、Javaってのはやはりでかくなり過ぎているのかも知れない。でかくなると身動きが鈍重(どんちょうじゃないのか……)になるくせに、知らないうちに火を焚いたり種を蒔いたり勝手にされていたりしてつじつまが合わなくもなる。
で、インターフェイスだが、あいつをクロージャの不格好な代替物として使わせるようにしたのは、どう考えても失敗だろう。全然インターフェイスの『相互に意味を与え合うオペレーションのまとまり』とは無関係に使うしかないからだ。それによって本来の意味合いも忘れられてしまうよ。
便利なインターフェイス(あらゆるメソッドの最後の引数にうってつけ)
public interface Action {
void invoke(Object[] args);
}
public interface Func {
Object invoke(Object[] args);
}
それに比べてdelegateというわけのわからないものを導入したヘルスバーグのほうがセンスがあるように思える。(が、後から後から追加で匿名メソッドとかラムダ式とか出てくるのはなんだかなぁではあるけれど。でも書きやすいから良いけど)
2011-02-23
_ RJBが思いもよらぬタイプのソフトウェアに組み込まれていて驚いた
作って公開したソフトウェアは自由だから、誰がどう使おうとどうでも良いのだが、それでも何に使われているのか興味がないと言えば嘘になる。特にRJBは想像以上に使われているようなので不思議だった。
それが、どうにもバグがあるらしくレポートをもらったのだが、一体なんのことだ? と首を傾げざるを得ない内容だ。というか、ploitという接尾辞はあまりにもこちらの想定外なものだし。
で、しばらく別件もあって放置していたら、ワークアラウンドなchangesetが出ていた。
でそれなりに有名なツールらしくて、へー、そういうところで活躍しているのか、と驚いた。(というか、RJBということは、Rubyのアプリケーションってことだな)
(それはそれとして、さてどういうバグなんだろうか。おれが表面的には無罪(無知だとしても)の可能性としては、JVMがコンパイルしたコードをヒープに確保するから、JVMをロードするプログラムはすべからくヒープ実行可能とすべきとか、なんだけどさすがにそんなことはないだろうから、スタックかヒープの境界を越えた書き込みをするバグがあるのだろうなぁ。と、とてもまずいので、allocaに頼っているところから順に潰していくとかなんだろうけど)
追記)いや、案外、おれが考えていることで当たりなのかも知れないぞ、とも思う。もしそうならば、JVMをホストしているのだから、SIGSEGVをトラップしてmprotectして返してやるのがこちらの使命なんじゃなかろうか? (他のプラットフォームで起きていないことや、paxctlで修正できるってところが怪し過ぎる)
paxカーネルって、そういうことだよね? 教えてえらい人。
追記:どうもそのようだ。
2011-02-26
_ tork03
西那須野へ行ってきた。
東京Ruby会議での高橋さんのスタイルがおもしろかったので、真似して多少のネタメモだけにしてアドリブ多用でやってみようとしたけど、さて楽しんでいただけただろうか(あるいは何か考えを深めるとか、見方を広げるとか、こちらの出した内容を遥かに上回るものを自分の内側から引っ張り出すためのトリガーになれただろうか)。というわけで、お付き合いくださってありがとうございました。
他の方の講演もそれぞれ興味深かったけど、樽家さんの字句解析の話は最後まで見たかったな。_tadさんのもそうだけど、開発のコンテキストがあるほうが(おれには)おもしろいのだが、LTでそれを入れると本題が完結しにくいというのが難点。(ということは、LTでは既知の技術トピックのコンテキスト話に終始させるか、コンテキスト抜きで技術のみに絞るかいずれかにせざるを得ないのかも知れない)
soraさんのテスト並列化のやつもおもしろかった。コア数の倍の成績が最も良いというのは(実メモリ搭載量に依存するとは思うが)、IO系のテストについてはプロセススイッチが行われるからそんなものだろうと思う(逆にfibみたいなのがコア数の倍で最も成績が良いとしたらハイパースレッディングが有効化されていて同時に動作する石の数がコアの倍ということだろう)。
というか、tork03は、実は裏でmrknさんが操っているのではなかろうかというくらい、mrknさんの影がちらつくところが面白かった。札幌と栃木は実は近い。
追記:思い出したけど、soraさんの正しいノコギリの使い方の解答は最高だった。require 'nokogiri'。あれは確かに挽きたいモノが挽ける。
2011-02-27
_ オーム社のプログラミングのための数学の本
以前、確かHaskellの集いのときだと思ったけど、オーム社の鹿野さんから『プログラミングのための確率統計』の話になって頂いたのだけど、完読してから書評を書こうとしたものの、1/3くらい読んだところで止まってしまったため、心苦しく思ってた。
止まってしまったのは読みにくいとかといったネガティブな問題じゃなくて、いよいよ自分でプログラミングしながら確かめながら読んだ方がいいなぁというところまで来た(つまり、書いてある内容を頭の中で検証するには無理がでてきた)からで、それをするには電車の中では無理だからだ(おれの通勤電車の場合)。
でも、あの本の、事象を面積として示すことで視覚化して理解を助けるという方法論はうまいと思う。少なくとも、おれは条件付き確率を完全に理解した。
 プログラミングのための確率統計(平岡 和幸)
プログラミングのための確率統計(平岡 和幸)というわけで、お勧めしておく。確率を押さえておく(復習しておく)ことは、何かと言えば障害発生「率」とかを相手にする商売なんだから必要だと思う。
で、それとは別に、tork03の抽選で、オーム社の同じシリーズの線形代数が当たった。
実のところ、マンガのやつが当たったと誤解して大喜びでマンガを持っていったら、違ったので少しがっかりした(マンガは池澤さんが当たったのだと思う)。
 マンガでわかる線形代数(信, 高橋)
マンガでわかる線形代数(信, 高橋)(やはり同世代人として、この潮流も見ておきたい気もするわけだが時間は有限なのでトリガーが必要)
でも、がっかりしたとは言え、同じ筆者グループだし、外れのはずはない(というか、当たったわけだし)。
で、こちらは読まなくても(多分、全部は読む気ないし)紹介できるので紹介しておく。というのは、前書きにえらくおもしろい箇所があったからだ。
以下、『丁寧に噛み砕いて説明しているけど、内容は薄いかも』と思った人への序文から引用。
堅い数学書は、コメントの少ないソースコードにたとえられます。驚くほど効率の良いエレガントなプログラムではありますが、「理解」するには、コードから意味を読みとる努力・教養・センス(誇張すればリバースエンジニアリング)が要求されます。一方、やさしい入門書は、油断すると、「コメントだけでコードがない」「コードの断片はあっても全体としては動作するプログラムをなさない」のようになるおそれがあります。本書のスタイルは、「完動するコードにコメントをたっぷり付ける」(見事な脚注が入る―引用者注)。そのコメントも、
# p を 1 増やす
p = p + 1
ではしょうがなくて、(略)
わかってるなぁ。
と、こういうわかっている人が自分の専門分野(数理工学の研究者と名乗っている)について書いているのだから、そりゃわかる本になるのは当然だろう。
 プログラミングのための線形代数(和幸, 平岡)
プログラミングのための線形代数(和幸, 平岡)というわけで、別の読み方として、正しいコメントの記述方法の考え方(というのは、プログラミングそのものの本ではないのでコードが出ているわけではない)を学ぶというメタリーディングもできそうなのであった。
# 注)アマゾン評を眺めていて気付いたが、「プログラミングのための」というのは、「このくらいの知識を持っていればプログラミングに利用できる」とか「プログラミングで利用するための前提としてこのくらいを押さえておくべき」というような意味であって、プログラミングのためのコピペ元という意味ではない(というか、それはプログラミングではなくてコーディングだ)。そういうものを期待していると、放り投げたくなると思う。
2011-02-28
_ シャープのガラパゴスケータイの写真はすごもの
友人が、東芝系の会社に勤めているのに、なぜかガラパゴスを持っていて、それを見せびらかす。
―どうだ、この待ち受けのアイコン群!
うむ、確かに浮かび上がっていておもしろい。が、それほどうらやましくもないなぁ。
―では、写真を撮って見せよう……うむ、失敗した。これが結構大変でタイムラグがあって……
少しもうらやましくないぞ。
というようなやり取りがあったのだが、ちゃんと撮れた写真を見せてくれた。
すげー。
 ガラパゴスのふしぎ (サイエンス・アイ新書)(NPO法人 日本ガラパゴスの会)
ガラパゴスのふしぎ (サイエンス・アイ新書)(NPO法人 日本ガラパゴスの会)
ちゃんと手前のものは手前、後ろのものは後ろに見える。浮かんでいるものと沈んでいるもの。しかし、すごく気持ち悪い。たとえば、人間の顔といったある程度同じような色温度(か何か、とにかく機械合成のキーとなるファクタ)を平面的にまとめることで差を出しているようなのだ。押絵に似ていなくもない。あるいは、段ボールで等高線を表現して作った立体地図とか。
とにかく、部分部分が妙に平面的なのだ。でも、全体としては遠近感が強力。
うらやましくはないが、すごく(良い意味で)おもしろかった。多分、最初にウォルターカーロスのバッハを耳にしたときとか、そういった感じ。
ジェズイットを見習え |
_ jun66j5 [セルを1つずつ設定するのではなくて、1行ずつ(もしくは複数行)設定していけばもっと早く出来ると思います。 https..]
_ arton [おお、そうですね。サンプルコードありがとうございます。 でも上のコードの要点は、外部プロセスサーバ呼び出しは遅いとい..]